




As AI and Large Language Models (LLMs) grow in popularity, they bring massive amounts of complex data that need to be processed efficiently. Traditional databases struggle with this high-dimensional data, similar to trying to find a needle in a haystack. Vector databases, however, are built for these massive datasets, allowing for fast, accurate searches, which is key for AI applications like recommendation systems and content retrieval.
Think of it this way: If you’re working with a traditional database, you’d have to search through all the text or images one by one. But with a vector database, the data is organized into vectors, which are just lists of numbers that represent key features of each object. This makes searching much faster because the system compares numbers instead of entire documents or images.
What is a Vector?
A vector is essentially a list of numbers that represent important features of an object, like an image or a sentence. For example, imagine you’re building an app that recognizes animals. An image of a cat might be turned into a vector that describes its color, size, and shape. A vector for a lion would have different numbers for size and color but might be similar in terms of shape.
Now, instead of the system manually scanning each image to see if it’s a lion or a cat, it simply looks at the vectors and finds the closest match. This is way faster than traditional methods and is a game-changer when dealing with millions of images or text entries.
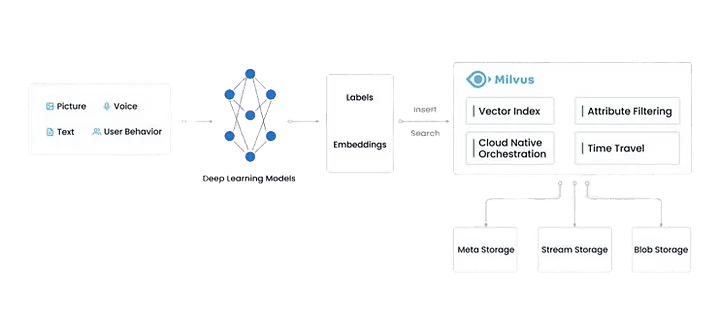
Embeddings: The Backbone of AI Models
When it comes to AI, especially models like LLMs, embeddings play a huge role. Embeddings are specialized vectors that reduce complex data (like sentences or images) into a simpler form while preserving important relationships between objects.
For instance, let’s say you’re building a chatbot. The word "happy" might have a vector that’s close to "joyful" because they mean similar things. On the other hand, "sad" would have a vector far away from "happy" because their meanings are different. By using embeddings, your chatbot can understand that "happy" and "joyful" are related, making its responses smarter.
How Vector Databases Store Data
Vector databases store data by turning each object into a vector using embeddings. Let’s imagine you have an app that recommends music. Each song can be represented as a vector with numbers describing its tempo, genre, and mood. When a user searches for songs similar to one they like, the vector database compares the vectors for all the songs and finds the ones with the closest match.
This means you don’t have to manually tag every song with “happy” or “fast tempo”—the vector database handles it. It understands the relationships between songs based on their embeddings and can suggest similar music without needing a direct match.
How Do Vector Databases Work?
Here’s a simple breakdown of how vector databases operate:
- User Query: Let’s say someone searches for an image of a "golden retriever." The system turns this search into a vector (like a numerical description of the dog).
- Embedding Creation: This vector captures the important features of a golden retriever, such as its color, size, and shape.
- Database Comparison: The vector is compared to all the other vectors stored in the database—say, a cat, a horse, and other dogs. The database uses mathematical methods (like cosine similarity) to find the vectors closest to the golden retriever.
- Output Generation: The system then shows images of dogs that match the query, prioritizing golden retrievers based on the similarity of their vectors.
- Real-time Updates: When you add more images of dogs, the database instantly updates the embeddings, meaning new golden retrievers will show up in future searches without any delay.
Key Benefits of Vector Databases for Developers
Here’s why vector databases are important for developers working on AI and machine learning projects:
- Efficient Similarity Search: Say you’re building an app that recommends products. With a vector database, you can easily find products similar to what a user has liked, whether it’s books, music, or even furniture. The database uses vectors to find related items without needing exact matches.
- Handling High-Dimensional Data: AI and machine learning models generate tons of data that are complex and multidimensional. Traditional databases get bogged down when handling this type of data, but vector databases are designed to manage it efficiently.
- Real-time Performance: Vector databases are built to provide fast results, even with huge datasets. This is key for things like recommendation engines, fraud detection, or real-time analytics, where you need quick answers.
- Personalization: If you’ve ever used a recommendation system, like Netflix or Spotify, you’ve experienced the power of vector databases. They enable apps to personalize recommendations based on your behavior, finding patterns in your data and suggesting things you’ll likely enjoy.
- Scalability: Whether you’re handling thousands or billions of data points, vector databases scale effortlessly. This means they’ll grow with your application as your data increases, without a drop in performance.
Popular Vector Database Solutions for Developers
Here are some top vector database solutions to consider:
- Weaviate: This is an open-source vector database that supports a wide range of data types, from text to images and audio. Weaviate is known for its seamless integration with machine learning frameworks like Hugging Face, OpenAI, and LangChain. It also offers real-time vector search and automatic indexing, making it a great choice for developers handling diverse data sources.
- Pinecone: This is a fully managed cloud-based solution designed for high-speed and scalable ML applications. Pinecone excels at similarity searches and provides real-time updates, making it ideal for applications requiring high throughput, such as recommendation engines and content retrieval.
- Milvus: Milvus is built for large-scale similarity searches and features a distributed architecture that separates storage from compute, making it perfect for managing dense datasets in AI applications. Milvus supports both on-premise and cloud deployment, offering flexibility for different project sizes.
- Qdrant: Qdrant offers fast, scalable vector similarity searches with additional payload support, allowing for more detailed and nuanced searches. It integrates easily with machine learning workflows and is a great option for applications that require both speed and precision in vector search.
- Chroma DB: Chroma DB is an open-source vector database designed primarily for storing and retrieving embeddings. It is well-suited for use in machine learning workflows and supports multi-modal data types, making it ideal for tasks like semantic search or cross-language text matching. Chroma DB offers a flexible storage system with both in-memory and persistent options, making it easy to scale depending on your project’s needs.
The Importance of Vector Databases in Today’s Data Landscape
With data getting more complex and massive, vector databases are becoming essential in fields like healthcare, finance, and e-commerce. For example, they’re used in healthcare to compare genetic data or in finance to detect fraud in real time. They’re also crucial for providing personalized user experiences in apps like streaming services or e-commerce platforms.
Developers working on AI-powered applications need to use vector databases to efficiently manage huge datasets, provide real-time responses, and offer personalized recommendations. These databases are built to scale, making them essential tools for handling millions of queries and data points in modern applications.
By incorporating a vector database into your projects, you’ll ensure your applications run smoothly and provide users with fast, accurate results—even as your data continues to grow.
Junior React Native Developer
If you like this article, we're sure you'll love these!


Are OpenAI’s Vector Databases Good Enough for Your Needs?
Discover whether OpenAI’s Embeddings API is the right fit for your vector search needs. Compare it with top vector databases like FAISS, Pinecone, Milvus, and Weaviate.


Knowledge Management: Applications for Modern Enterprises
Explore smarter ways to manage knowledge that drive efficiency, innovation, and seamless team collaboration



